
Zeitreihen Modelle [Teil 2]: Zeitreihen mit langem Gedächtnis
Wie gut ist Dein Gedächtnis? - Zeitreihen mit langem Gedächtnis
Einführung
In unserem letzten Artikel [Zeitreihen Modelle - Teil 1] haben wir verschiede Varianten der ARMA-Modelle näher betrachtet. Darauf aufbauend möchten wir in diesem Artikel eine Einführung über Zeitreihen mit langem Gedächtnis geben. Diese Eigenschaft ist in Finanzzeitreihen sowie in der Natur weit verbreitet.
Langes Gedächtnis
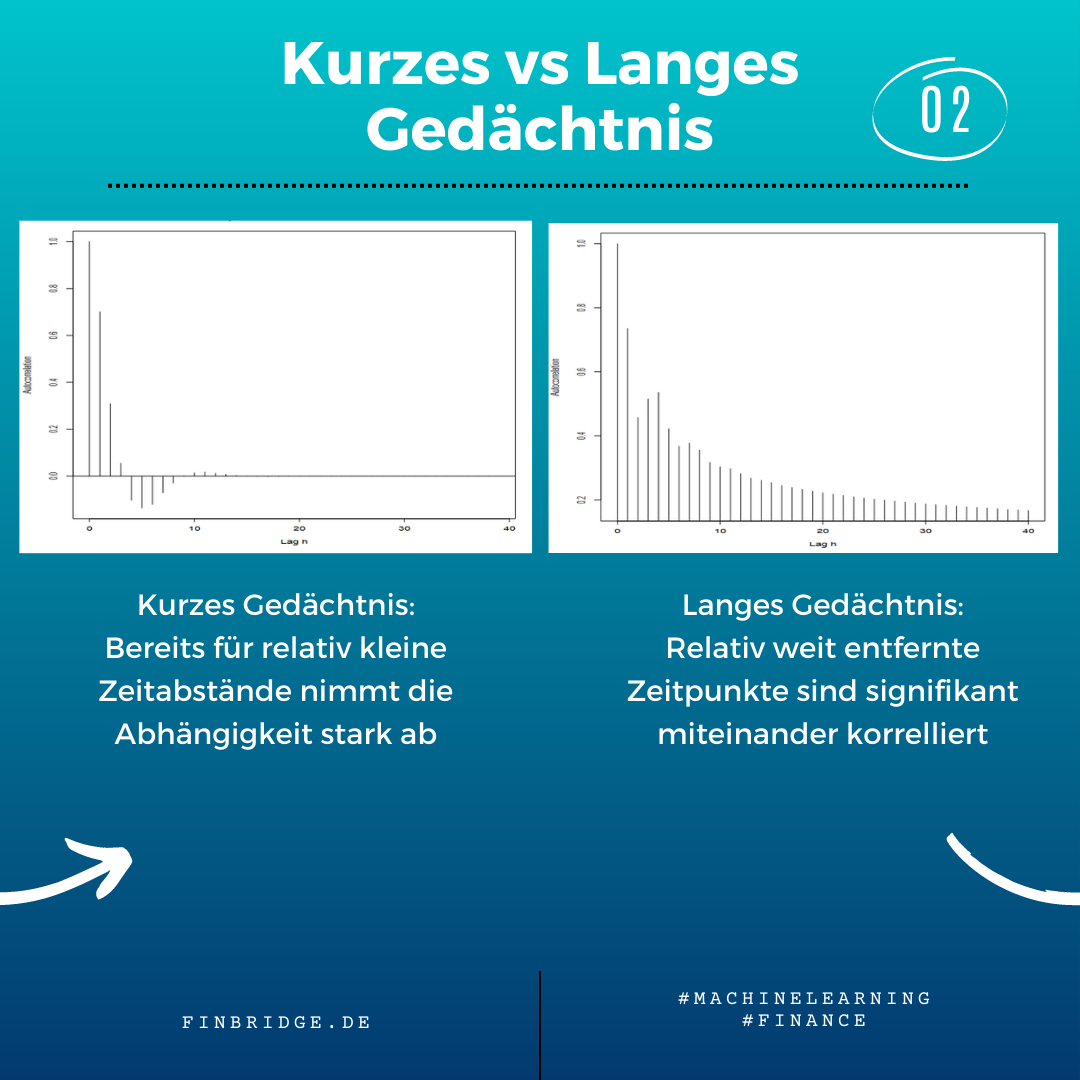
Autokorrelationsdiagramme bestimmter Zeitreihen weisen eine potenzgesetzartige Struktur auf. Das bedeutet, dass die Werte weit entfernter Zeitpunkte stark miteinander korreliert sind. Im Gegensatz dazu, geht analog die Korrelation bei Prozessen mit kurzem Gedächtnis exponentiell gegen Null.
Das ARFIMA-Modell
Das ARFIMA-Modell ARFIMA(p, d, q) steht für Autoregressive Fractionally Integrated Moving Average. Es ist eine Erweiterung des im Teil 1 vorgestellten ARIMA-Modells, da es im Gegensatz zu diesem auch nicht-ganzzahlige Werte für den Differenzenparameter d zulässt.

Zeitreihen-Modell ARFIMA(p, d, q)

Backshift Operator

AR Filter

MA Filter
Die fraktionelle Differenzierung ermöglicht es bei Zeitreihen mit langem Gedächtnis Stationarität zu erreichen. Dies bedeutet, dass im Zeitverlauf die statistischen Eigenschaften einer Zeitreihe wie z.B. Mittelwert, Varianz oder Kovarianz konstant bleiben.
Bei einem Prozess mit langem Gedächtnis liegt der Parameter d zwischen 0 und 0.5. Von einem antipersistenten Prozess spricht man bei Werten zwischen -0.5 und 0. Bei diesem folgen auf große, positive Werte tendenziell große, negative Werte und dies über lange Zeitabschnitte hinweg (dargestellt in der Veranschaulichung im Karussell unterhalb). Analog gilt dies ebenso für betragsmäßig kleine Werte.
Der Parameter d lässt sich auf unterschiedliche Weisen schätzen. So sind neben neben (Quasi-) Maximum Likelihood Methoden auch robuste Regressionen, wie z.B. M-Regression möglich. Andere Möglichkeiten sind die R / S Analyse und die Gewele & Porter-Hudack Regression.
Ein ARFIMA-Modell für realisierte Volatilitäten
Im Banken- und Finanzsektor sind die Schwankungen von beispielsweise Aktien oder Finanzinstrumenten von Bedeutung. Bei der Prognose dieser Schwankungen (Volatilitäten) können ARFIMA-Modelle verwendet werden. Die Schwankungen lassen sich gut durch realisierte Volatilitäten (RV) modellieren, die auf Basis von Intraday-Renditen berechnet werden. Dabei ist die Verteilung logarithmischer RV gut durch eine Normalverteilung approximierbar. Auf dieser Grundlage kann ein ARFIMA-Modell der logarithmischen RV durch Gaussian Maximum Likelihood geschätzt werden. Durch das geschätzte Modell lassen sich dann zukünftige Volatilitäten prognostizieren.
Der Artikel ist unterhalb in Form eines Karussells dargestellt.






![097N - Head Zeitreihen mit langem Gedächtnis [Teil 2].png](https://images.squarespace-cdn.com/content/v1/54f9ea6be4b0251d5319ad8b/1679518052232-8OVL8GT9P49HCGGQ80O0/097N+-+Head+Zeitreihen+mit+langem+Ged%C3%A4chtnis+%5BTeil+2%5D.png)
Erstellt von Dr. Carsten Keller und Patrick T. Philipp
Referenzen im Karussell
[1] Holan, Scott & Lund, Robert & Davis, Ginger. (2010). The arma alphabet soup: A tour of ARMA model variants. Statistics Surveys. 4. 10.1214/09-SS060.
[2] Lux, Thomas & Morales-Arias, Leonardo & Sattarhoff, Cristina. (2011). A Markov-switching Multifractal Approach to Forecasting
[3] Realized Volatility. Schlittgen, R. and Sattarhoff, C. 2020. Angewandte Zeitreihenanalyse mit R. Berlin, Boston: De Gruyter Oldenbourg. https://doi.org/10.1515/9783110694390
[*]: Link abgerufen am 30.01.2023
[**]: Die Verlinkungen verweisen auf externe Daten außerhalb unserer Domain. Trotz sorgfältiger inhaltlicher Kontrolle übernehmen wir keine Haftung für die Inhalte externer Links.
Erfahren Sie mehr zum Thema Grundlagen:
Neugierig?
Entdecken Sie mehr über unsere Machine Learning Techniken
Wir stehen Ihnen bei Fragen zur Verfügung!