Features
25 Jan 2021An Introduction to Disambiguation



What is disambiguation, why is it important and what does it do? One of Adarga's Machine Learning Engineers, Sebastian, explains.

Crime is on the rise in London! Here, in the UK, we would feel alarmed by this headline as we subconsciously link the alias ‘London’ to the UK’s capital. However, this is a view biased by our individual points of reference and highlights the importance of disambiguating words in a text correctly. A tautological – but nevertheless intuitive – definition of disambiguation is ‘the reduction or elimination of ambiguity’.
The ambiguity we need to remove concerns named entities. Wikipedia defines a named entity as "a real-world object, such as persons, locations, organizations […] that can be denoted with a proper name". Boris Johnson, Donald Trump, SARS-CoV-2, WHO: all of these would be considered named entities. Disambiguation links the named entities to a unique identifier (such as code, hash, number sequence). This seems trivial but it produces pitfalls, even for humans. Some terms are unambiguous. When we hear SARS-CoV-2 we immediately know what this refers to: it is a unique word, created to only describe a single phenomenon.
Now, what if you knew that the above headline was actually taken from a newspaper in southern Ontario (Canada) and that the full sentence reads “Crime is on the rise in London which is of grave concern to the regional government in Ontario”? This would shift the meaning of the sentence to the west by some 3,600 miles to one of Canada’s largest cities with the same alias. This is an example of polysemy - multiple meanings for the same alias – and is just one of many challenges that humans resolve whilst reading.
The question that subsequently arises is: how can we teach machines to accurately complete this task?
Knowledge Base
For a machine, the goal of disambiguation can be viewed as correctly linking an entity in text to a unique identifier within a knowledge base. A knowledge base is just a collection of said identifiers and additional attributes. One well-known example of a knowledge base is Wikipedia. It offers such a unique identifier in the form of Q-codes for the globally most prominent named entities.
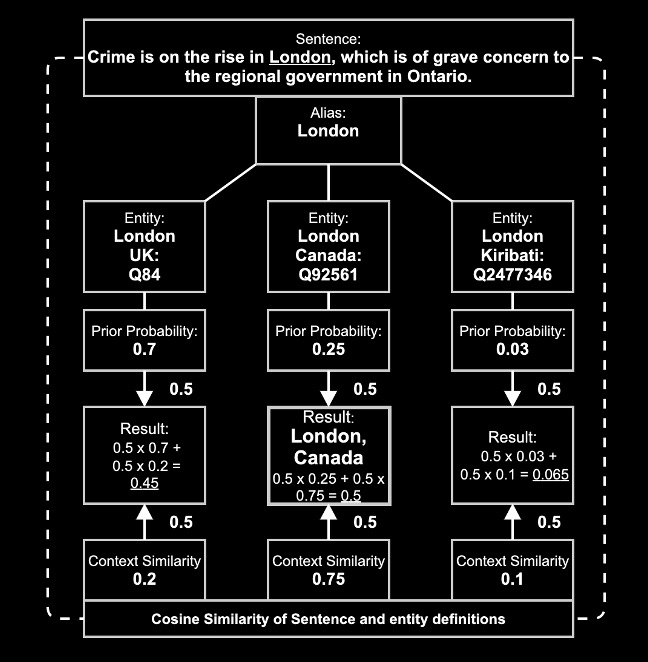
‘London’ (UK) is represented by the identification code Q84, while ‘London’ (Canada) and the village ‘London’ in Kiribati are assigned the codes Q92561 and Q2477346, respectively.
Besides offering unique identifiers, we can use Wikipedia to generate probabilities of an entity given an alias. One way to approximate such probabilities is by simply counting how many times the alias ‘London’ links to any of the different entities it can represent throughout Wikipedia. So, if there are 700 hyperlinks that link the alias ‘London’ to Q84 and there are 1000 hyperlinks with this alias in the whole Wikipedia corpus, we can infer that the prior probability of ‘London’ referring to the UK’s capital is 70%.
Unfortunately, prior probabilities are not enough for accurate disambiguation.
You might have already spotted an issue here. If we always take the highest probability, there will only ever be one entity assigned for any alias: London (UK) would hence be assigned to all ‘London’ aliases. However, assuming that the prior probabilities represent the entirety of text in our world well-enough, this will still give us the correct result in 70 percent of the cases for London.
But is there a way to account for rare entities and edge-cases? When encountering Ontario’s mention in the initial example, most of us would hesitate and try to adjust our initial choice based on this new piece of information; we would update our internal probability calculations to account for context.
Context
One way to measure or incorporate context is to check for the similarity between the sentence that an entity is found in with a definition of the entity itself. Wikidata’s definition for London (Q84) is ‘capital and largest city of the United Kingdom’, whereas London’s (Q92561) states ‘city in Southwestern Ontario, Canada’.
A basic way of measuring similarity could be word overlap. For our initial sentence ‘Crime is on the rise in London, which is of grave concern to the regional government in Ontario’, the overlap with the two definitions from above is ‘the’ and ‘of’ for the UK’s capital and ‘in’ and ‘Ontario’ for Canada’s London. Adjusting for the length of the definitions gives us 2/8 and 2/5, respectively. Since 2/5 or 0.4 is larger than 2/8 or 0.25, the correctly identified winner would be London (Canada). However, this approach is error-prone and susceptible to frequently used words.
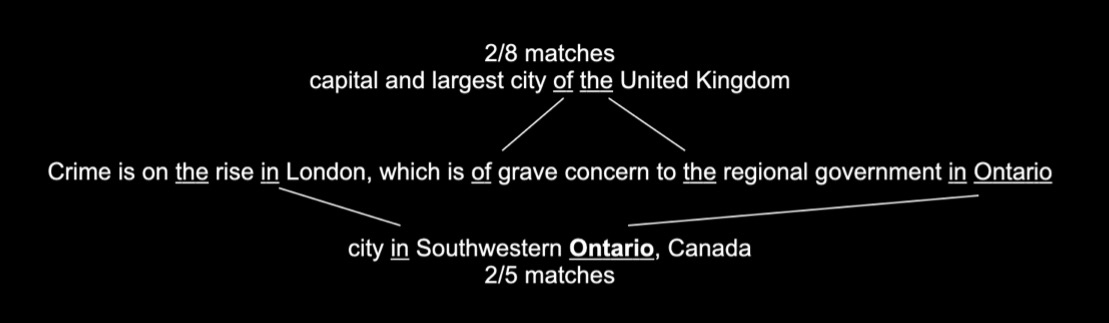
Ignoring so-called ‘stop-words’ – words that are highly prevalent in the English language (such as the, in, and, or etc.) – creates an even more obvious winner with 1/5 vs. 0/8.
However, identifying overlap is not a reliable way to determine similarity. It fails whenever a connection is not explicitly specified in a text.

Hence, a more sophisticated approach is needed. One such approach would be to increase the level of abstraction and cast words or whole sentences into a numerical vector space. Such a representation is called word or sentence embedding.
Word embeddings can be used to calculate how similar words are and are created by performing language tasks in a neural network. Predicting a word from its context or context from a word, sequence, or missing word predictions; these are all examples of such tasks. The aim of this method is to learn an optimal numerical representation of each word and hence to create a unique vector representation for every word in a predefined vocabulary.
Such a representation allows us to perform calculations with words. This means that words such as ‘home’, ‘house’ or ‘animal’ could be represented by the vectors:
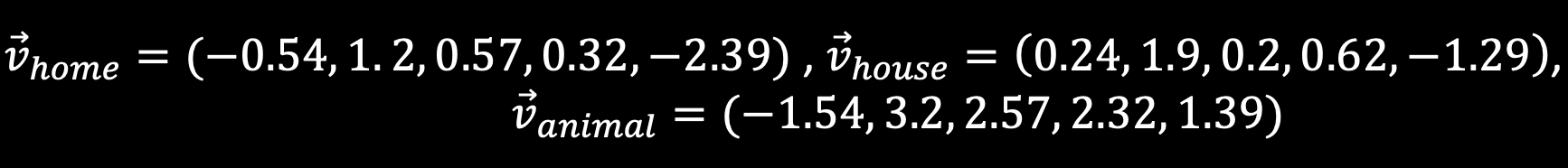
Language is rich in ambiguity and variety and casting a word into a low dimensionality embedding– as shown here – will not capture many of its subtleties. Hence, embeddings used in practice are significantly larger, going into hundreds of dimensions.
However, even this toy example enables us to calculate the similarity between those words. Calculating the cosine-similarity (the angle between two vectors) of the above mentions gives us a similarity value of 0.82 for ‘home’ and ‘house’ but only 0.25 for ‘home’ and ‘animal’, where the similarity values represent the semantic closeness of the terms.
This approach can be extended to sentences by averaging the word embeddings before calculating similarity or other, more sophisticated, methods.
Conclusion
We have discussed how to link a word (an alias) to a knowledge base in order to get possible entity matches for it, how to calculate the prior probability of an entity being referred to by this alias, and how to calculate the similarity between an alias’ context and a stored definition for each entity candidate.
A simple way to determine which entity to link to is to apply the average of prior probability and context score and subsequently choosing the entity with the highest weighted average. Combining all these steps gives us an algorithm that allows a machine to perform automated disambiguation.
This article meant to serve as an accessible introduction to the topic of disambiguation for anyone interested in learning the basics of this branch of Natural Language Processing (NLP). It is one of the many NLP tasks we perform here at Adarga.