<style>
/* reduce from default 48px: */
.reveal {
font-size: 24px;
text-align: left;
}
.reveal .slides {
text-align: left;
}
/* change from default gray-on-black: */
.hljs {
color: #005;
background: #fff;
}
/* prevent invisible fragments from occupying space: */
.fragment.visible:not(.current-fragment) {
display: none;
height:0px;
line-height: 0px;
font-size: 0px;
}
/* increase font size in diagrams: */
.label {
font-size: 24px;
font-weight: bold;
}
/* increase maximum width of code blocks: */
.reveal pre code {
max-width: 1000px;
max-height: 1000px;
}
/* remove black border from images: */
.reveal section img {
border: 0;
}
.reveal pre.mermaid {
width: 100% !important;
}
.reveal svg {
max-height: 600px;
}
.reveal .scaled-flowchart-td pre.mermaid {
width: 100% !important;
/* why? float: left; */
}
.reveal .scaled-flowchart-td svg {
max-width: 100% !important;
}
.reveal .scaled-flowchart-td svg g.node,
.reveal .scaled-flowchart-td svg g.label,
.reveal .scaled-flowchart-td svg foreignObject {
width: 100% !important;
}
.reveal .scaled-flowchart-td p {
clear:both;
}
.reveal .centered {
text-align: center
}
.reveal .width75 {
max-width: 75%;
}
</style>
# Layout-Analyse für Tabellen-Dokumente <!-- .element: class="centered width75" -->
Robert Sachunsky, Dr. Andreas Niekler <!-- .element: class="centered width75" -->
---
## Übersicht
- [Persönliches](#/2)
- [Arbeitsplanung](#/3)
- [Einordnung (Texterkennung / Textmining)](#/4)
- [Problemstellung (Heizkostenabrechnung)](#/5)
- [Lösungsansatz 1: partielle Layoutanalyse / monolithisch](#/6)
- [Lösungsansatz 2: komplette Layoutanalyse / modular](#/7)
- [Daten-Bedarf](#/8)
---
## Persönliches
### Prof. Dr. Gerhard Heyer
- Vita:
- Dr.phil. Mathematische Logik und Linguistik
- Uni Cambridge (UK), Uni Bochum, Uni Michigan (USA)
- Triumph-Adler AG
- Uni Leipzig (Professur seit 1994)
- Forschungsschwerpunkte:
- automatische Sprachverarbeitung, semantische Analyse und Repräsentation von Text
- Wissensverarbeitung, KI-Anwendungen
----
## Persönliches
### Dr. Andreas Niekler
- Ausbildung:
- Dr.-Ing. Informatik
- Dipl. Ing. Medientechnik
- HTWK Leipzig, University of West Scotland, Uni Leipzig
- Projekte:
- Data Mining und Wertschöpfung
- ATMT Workbench
- Corpus Miner, DEVal
----
## Persönliches
### Robert Sachunsky
- Ausbildung:
- Dipl.-Ing. Informationssystemtechnik (Sprachverarbeitung/Computerlinguistik)
- TU Dresden, King's College London
- Projekte:
- Eurofon (spontansprachl. semant. Übersetzer)
- Uni Leipzig: OCR-D
---
## Arbeitsplanung
### Arbeitspakete
- AP 4: Forschung und Entwicklung
- Softwaremodule für die Texterkennung, Layoutanalyse, Tabellenextraktion und Informationsextraktion der relevanten Informationen aus der HKA.
Die Module werden als Open-Source-Komponenten zur Verfügung gestellt.
- AP 1: Projektmanagement
- PostDoc Anteile, Koordination, Publikation
----
## Arbeitsplanung
### Meilensteine
- M2, M3, M10, M13
- M2 Open-Source-Software ist weitestgehend fertig
- M3 erfolgt derzeit; es müssen wesentlich mehr Daten her
- M10 eher Alpha als Beta
- M13 Beta
----
## Arbeitsplanung
### Ziele
- Fortschritt und Expertise bei der Layouterkennung in Tabellen
- Fortschritt in der Dateninterpretation von Tabellen
- Open-Source-Software-Komponenten für die Nachnutzung und den Transfer
- Kompetenzaufbau Dokumentverarbeitung technischer Dokumentation
---
## Einordnung (Texterkennung / Textmining)
- künstliche Intelligenz
- regelbasiert
- Algorithmen, parametrische Modelle
- wissensbasiert
- Logik, Wissensrepräsentation
- maschinelles Lernen
- Deep-Learning
----
## Einordnung (Texterkennung / Textmining)
### Texterkennung
0. <!-- .element: style="color:gray" -->
Import/Aufbereitung von Bilddaten
- Formatkonversion, Farb-Normalisierung
- Trennung von Doppelseiten
- Metadaten
1. <!-- .element: style="color:gray" --> Bildvorverarbeitung
- Beschneidung und Skalierung
- Deskewing und Dewarping
- Binarisierung
2. Layout-Analyse (OLR)
- Segmentierung in Regionen und Klassifizierung
- Reihenfolge-Detektion
- Segmentierung in Textzeilen
- <!-- .element: style="color:gray" --> Schrift-/Sprachklassifizierung
3. <!-- .element: style="color:gray" --> Zeilen-Erkennung (OCR)
- CNN+LSTM+CTC
4. <!-- .element: style="color:gray" --> Nachkorrektur
5. Dokument-Analyse
----
## Einordnung (Texterkennung / Textmining)
### Texterkennung
#### Layout-Analyse: Mask-RCNN
- Multitask-Learning für Objekterkennung von Regionen:
- Klassifikation
- Bounding-Box-Regression
- Pixelmaske innerhalb der BBox

----
## Einordnung (Texterkennung / Textmining)
### Texterkennung
#### Layout-Analyse: Mask-RCNN
||||
----
## Einordnung (Texterkennung / Textmining)
### Textmining
> Bündel von Algorithmus-basierten Analyseverfahren zur Entdeckung von Bedeutungsstrukturen aus un- oder schwachstrukturierten Textdaten. [Wikipedia]
0. Daten: Textfragmente der Seite
1. Verfahren: maschinelles Lernen
- CNN, Graph Embeddings, geometrische Relationen
- Kontextinformationen
- Physikalische Einheiten, Wortbedeutungen
3. Externe Daten:
- Wissensgraphen
**Klassifikationsidee**: Text Block in its Context...
----
### [KIM CNN 2014](https://www.aclweb.org/anthology/D14-1181/)

----
### Word Embeddings [Explained](http://jalammar.github.io/illustrated-bert/)
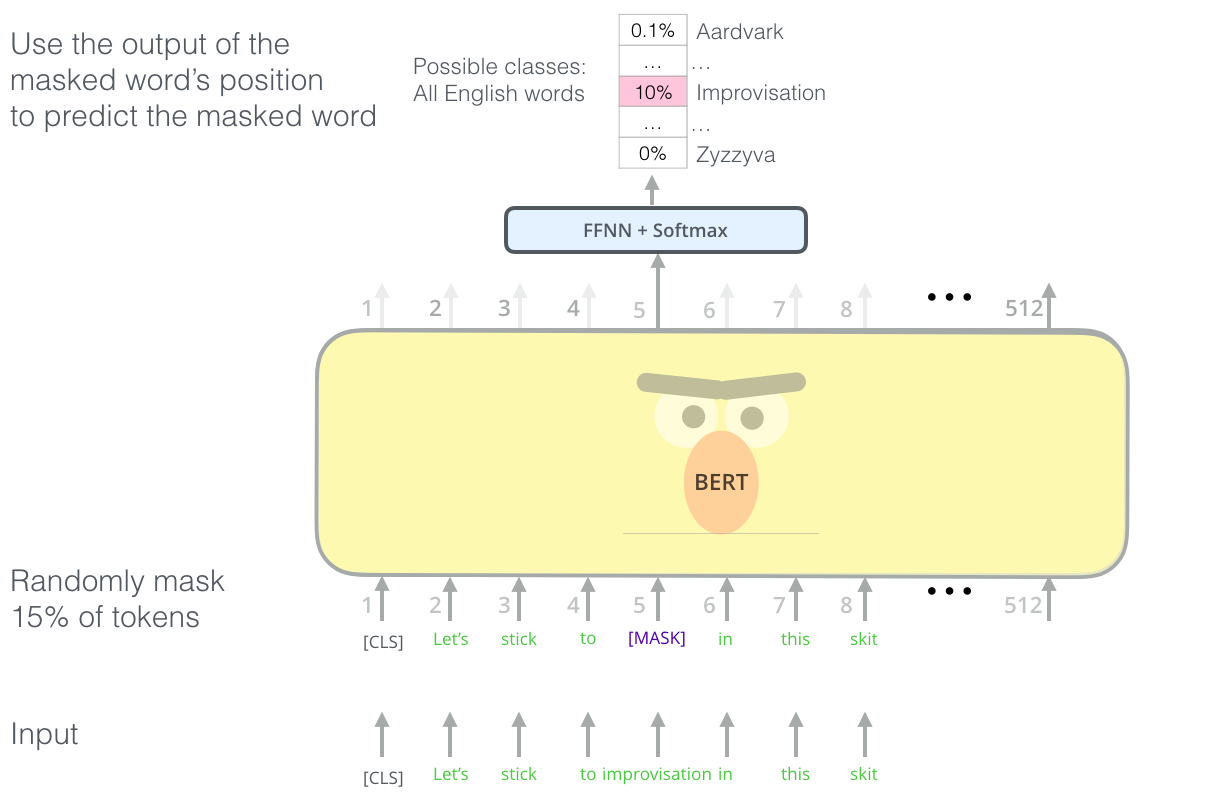
----
### Graph Embeddings [Explained](https://towardsdatascience.com/graph-embeddings-the-summary-cc6075aba007)
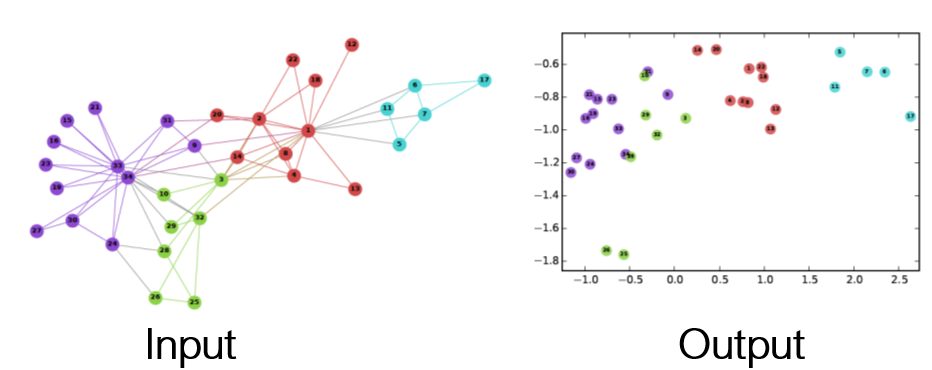
---
## Problemstellung (Heizkostenabrechnung)
- Abrechnugsstart
- Abrechnungsende
- Postleitzahl
- Gebäudefläche
- Wohnungsfläche
- Energieträger
- Verbrauch Energieträger (Anzahl)
- Verbrauch Energieträger (Einheit)
- Verbrauch Energieträger (Kosten)
- Verbrauchseinheiten des Gebäudes
- Verbrauchseinheiten der Wohnung
- Verbrauchseinheiten (Einheit)
- Verbrauch Warmwasser (m³ oder kWh oder mWh)
- Kosten des Kaltwassers für Warmwassererzeugung
- Heizkosten des Gebäudes für Raumwärme
- Heizkosten des Gebäudes für Warmwasser
- Anteil Grundkosten für Raumwärme
- Anteil Grundkosten für Warmwasser
<!-- .element: class="fragment" data-fragment-index="1" -->
Eigentlich: mehrere Fallunterscheidungen → Entscheidungsbaum
<!-- .element: class="fragment" data-fragment-index="2" -->
- Ein-, Zwei-, Mehrfamilienhaus
- Haus-, Wohnungseigentümer, Mieter, Verwalter
- Zentralheizung, Etagenheizung, Nachtspeicher
- Keller, Warmwasserbereitung ...
<!-- .element: class="fragment" data-fragment-index="2" -->
----
## Problemstellung (Heizkostenabrechnung)
Wie geht der Mensch vor?
<!-- .element: class="fragment" data-fragment-index="0" -->
<table><tr><td>Wohnfläche:</td><td><img src="https://i.imgur.com/Q8V7ps3.jpg" width="500"/></td></tr></table>
<!-- .element: class="fragment" data-fragment-index="1" -->
<table><tr><td>Anteil Grundkosten Heizung:</td><td><img src="https://i.imgur.com/76LzLdR.jpg" width="500"/></td></tr></table>
<!-- .element: class="fragment" data-fragment-index="2" -->
<table><tr><td>Verbrauchseinheiten (Gebäude):</td><td><img src="https://i.imgur.com/chN9Goq.jpg" width="500"/></td></tr></table>
<!-- .element: class="fragment" data-fragment-index="3" -->
<table><tr><td>Verbrauchseinheiten (Wohnung):</td><td><img src="https://i.imgur.com/T3JCXuF.jpg" width="500"/></td></tr></table>
<!-- .element: class="fragment" data-fragment-index="4" -->
<table><tr><td>Heizkosten Gebäude (Raumwärme):</td><td><img src="https://i.imgur.com/L16Zk5k.jpg" width="500"/></td></tr></table>
<!-- .element: class="fragment" data-fragment-index="5" -->
<table><tr><td>Verbrauch Energieträger (Anzahl):</td><td><img src="https://i.imgur.com/Frffi3O.jpg" width="500"/></td></tr></table>
<!-- .element: class="fragment" data-fragment-index="6" -->
<table><tr><td>Verbrauch Energieträger (Einheit):</td><td><img src="https://i.imgur.com/vVefq5f.jpg" width="500"/></td></tr></table>
<!-- .element: class="fragment" data-fragment-index="7" -->
<table><tr><td>Verbrauch Energieträger (Kosten):</td><td><img src="https://i.imgur.com/4wCtfz3.jpg" width="500"/></td></tr></table>
<!-- .element: class="fragment" data-fragment-index="8" -->
----
## Problemstellung (Heizkostenabrechnung)
### Herausforderungen
- Verschränkung von visueller und textueller Information
- sehr komplexe Layouts
- hohe sprachliche Varianz
- redundante Einträge, aber auch mehrseitige Layouts
- Semantik (Addition, Subtraktion, Multiplikation, Division)
---
## Lösungsansatz 1: partielle Layoutanalyse / monolithisch
- Grundidee: partielle Layoutanalyse einfacher, relevant nur ~13 Zahlenwerte
- implizite Modellierung logischer Tabellenstruktur:
- Freifeld-Zeilensegmentierung und OCR
- vektorielle Textrepräsentation mit klassen-spezifischen Modellen
- visuelles Segmentierungs- und Klassifizierungsmodell (z.B. [Mask-RCNN](https://arxiv.org/abs/1703.06870) oder [DecompNet](https://arxiv.org/abs/1511.06449)):
- direkt (1 Maske/Klasse pro Kennwert)
- Überlagerung von Bild-Rohdaten mit Textvektoren
- OCR und Extraktion
---
## Lösungsansatz 2: komplette Layoutanalyse / modular
- Grundidee: trennbare Teilprobleme (leichter erlernbar, verschiedene Datenquellen)
- explizite Modellierung logischer Tabellenstruktur:
- visuelles Segmentierungs- und Klassifizierungsmodell (Mask-RCNN):
- für Regionen (1 Maske pro Region, Klassen: Bild/Text/Tabelle/...)
- visuelles Segmentierungs- und Klassifizierungsmodell (Mask-RCNN):
- für Tabellen-Zellen (1 Maske pro Zelle, 1 Klasse)
- Zeilensegmentierung in Regionen/Zellen und OCR
- evtl.: Textklassifikation und visuelles Subklassifizierungsmodell:
- Textregionen: Fließtext, Überschrift, Seitenzahl, Adresse...
- Adresse: Anschrift, Absender, Kontakt...
- Tabelle: Kopf vs Zelle (links-rechts, oben-unten)
- Bild, Graphik, Logo, Handschrift, Stempel...
- Erkennung der Baum/Graph-Struktur der Tabellen-/Textregionen
- regelbasierte Extraktion
---
## Daten-Bedarf
### Groundtruth für Ansatz 1
- Bilder mit Einfärbungen für jede Klasse (Multi-layer TIFF):
- Kontext <!-- .element: style="background-color:magenta" -->
- Kennwert <!-- .element: style="background-color:cyan" -->
- textuelle Varianten (Formulierungen) für Kontexte (Plaintext)
----
## Daten-Bedarf
### Groundtruth für Ansatz 2
- vollständige Annotation von Layout und Struktur (PAGE-XML):
- Regionen/Zellen (Polygon-Koordinaten und Klasse/Unterklasse)
- Zeilen (Polygon-Koordinaten)
- Textinhalt
→ aufwendig (v.a. wenn vollständig manuell erstellt)
----
## Daten-Bedarf
### Groundtruth für Ansatz 2
- externe Trainingsdaten für Layoutanalyse sind rar
- semi-automatische GT-Erzeugung
 <!-- .element: class="fragment" data-fragment-index="1" -->
 <!-- .element: class="fragment" data-fragment-index="2" -->
- Modell-Transfer von Standardproblemen <!-- .element: class="fragment" data-fragment-index="3" -->

{"metaMigratedAt":"2023-06-15T03:48:52.698Z","metaMigratedFrom":"YAML","title":"Layout-Analyse für Tabellen","breaks":"false","description":"Übersichtsfolien Auftakt-Treffen Smart-HEC","slideOptions":"{\"theme\":\"white\",\"slideNumber\":true}","contributors":"[{\"id\":\"c62f1b15-791a-47e1-8e4c-ab2ed00c04bc\",\"add\":16677,\"del\":6742},{\"id\":\"4e562848-776c-4b21-b326-1200b2e44f63\",\"add\":2920,\"del\":924}]"}