
Für die Optimierung einer Website für die Suchmaschinen ist es unumgänglich, zu wissen, wie eine Suchmaschine funktioniert.
Und genau das möchte ich dir in diesem Blogartikel näherbringen.
Suchmaschinen erklärt
Suchmaschinen (auch genannt: allgemeine Suchmaschinen, Web-Suchmaschinen Universalsuchmaschinen, algorithmische Suchmaschinen) haben den Anspruch, das Web möglichst komplett abzudecken. Aufgrund der Größe des Internets ist dies jedoch nicht möglich.
Web-Suchmaschinen konzentrieren sich auf bestimmte Inhalte: Dokumente, die auf Webservern abgelegt sind. Durch die Verlinkung zwischen den verschiedenen Dokumenten entsteht ein Netz (World Wide Web).

Suchmaschinen wie Lycos arbeiteten schon von Beginn an nach dem gleichen System wie Google heute: Die Dokumente im Web werden durch das Verfolgen der Verlinkungen zueinander erfasst.
Suchmaschinen sind solche, die Inhalte des Webs durch das Verfolgen von Verlinkungen erfassen, durch das sogenannte Crawling. Dabei startet das Crawling bei bekannten Dokumenten und folgt den Links. Dadurch werden neue Dokumente entdeckt, deren Verlinkungen ebenfalls verfolgt werden. So entsteht ein (unvollständiges) Abbild der Dokumente im Internet, das dann durchsuchbar gemacht wird.
Wichtig: YouTube ist keine echte Suchmaschine nach der Definition, da YouTube nur eine Suche nach den Videos auf der Plattform selbst erlaubt und nicht Videos im kompletten Word Wide Web abgebildet werden.
Weitere Suchmaschinen-Arten:
- Spezialsuchmaschinen: Sie liefern nur Dokumente zu bestimmten Websites, wie Kindersuchmaschinen (z. B. Frag Finn)
- Meta-Suchmaschinen: Bei einer Suchanfrage werden die Ergebnisse von einer oder mehreren „echten“ Suchmaschinen eingeholt. Beispiel: Metager.de – hier wird eine Vielzahl von verschiedenen Suchmaschinen abgefragt.
- Web-Verzeichnisse: Hier werden die Websites manuell von Menschen erfasst und im Index gespeichert – ein großer Unterschied zu aktuellen Suchmaschinen wie Google oder Bing!
Wie Suchmaschinen funktionieren
Zunächst: wenn wir mit einer Suchmaschine suchen, wird nie nach den Inhalten des Webs selbst gesucht, sondern immer nur auf eine aufbereitete Kopie des World Wide Web zurückgegriffen. Wie bereits erwähnt, gehen die Crawler von Seite zu Seite und folgen den dortigen Links, um weitere Dokumente zu finden. Die gefundenen Dokumente werden erst einmal im sogenannten „Local Store“ gespeichert. Dieser stellt das Rohmaterial für den Index dar. Durch einen sogenannten Indexer werden die Rohmaterialien aufbereitet, damit sie effizient durchsuchbar sind.
Es wird eine Art Repräsentation für jedes Dokument angefertigt und es werden Kategorien angelegt, um diese schnell auffinden zu können. Der Searcher hat die Vermittler-Aufgabe zwischen den abgespeicherten Informationen und dem Nutzer.
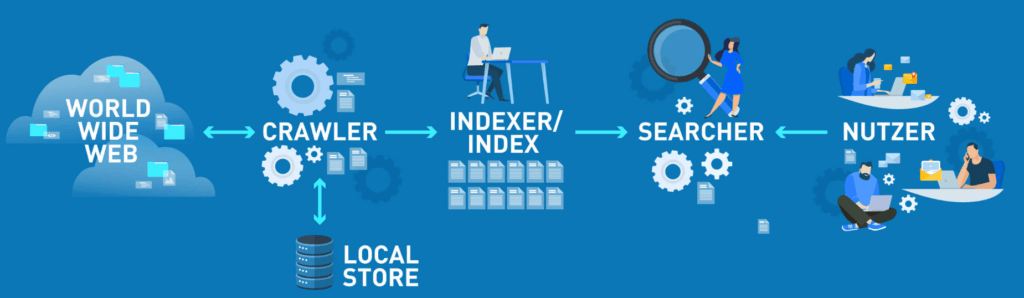
Beschaffung von Inhalten: Wie arbeitet der Crawler?
Das Word Wide Web (WWW) besteht vor allem aus Dokumenten im HTML-Format, welche eine eindeutige Adresse (URL) besitzen und über Links miteinander verbunden sind.
Über sogenannten Crawler erfassen Suchmaschinen die Dokumente im WWW und deren Verlinkungen zueinander. Die Crawler folgen diesen Verlinkungen und versuchen darüber möglichst alles im WWW zu finden. Dieses Ziel ist leider nie erreichbar, da es Seiten gibt, die nicht von Suchmaschinen-Crawlern erfasst werden wollen. Hier spricht man vom Deep-Web – das sind Seiten, die über ein Passwort geschützt sind oder nicht über entsprechende Verlinkungen verfügen.
Fehlende Verlinkungen sind generell ein Problem für die Crawler. Neue Websites, die über gar keine Verlinkung verfügen, können nicht gefunden werden. Alternativ finden Suchmaschinen neue Informationen über „Feeds“. Darüber werden den Suchmaschinen Informationen mitgeteilt. So stellen z. B. Onlineshops über einen Feed in Form von XML-Dokumenten den Suchmaschinen ihren Produktkatalog zur Verfügung. Auch normale Websites können den Suchmaschinen über eine XML-Sitemap zeigen, welche Inhalte auf ihrer Website zu finden sind.
- Exkurs:
- Website = eine komplette Domain
- Webseite = eine bestimmte Seite auf einer Domain
Das Crawling muss regelmäßig stattfinden, sonst findet die Suchmaschine keine neuen Inhalte oder aktualisierten Texte sowie neue Verlinkungen. Dabei werden stark verlinkte Websites und populäre Seiten häufiger besucht, da hier die Aktualisierungsintervalle oftmals kürzer sind (Beispiel: Nachrichten-Websites).
Ein Crawler kann nur Texte und die Strukturinformationen im Quellcode einer Website auslesen. Dokumente mit vielen grafischen Elementen, wie Bildern und Videos, und nur wenig Text können von den Crawlern daher nur schwer verstanden werden. Für die Suche und Erfassung nach bestimmten Dateien, wie Videos und Bildern, gibt es Crawler, die Inhalte für sogenannten Spezialsuchmaschinen, wie die Google Bildersuche oder Google Shopping, beschaffen. Bei der Bildersuche zum Beispiel kann der Crawler das Bild im HTML-Dokument erkennen und es mit Hilfe von zusätzlichen Informationen, wie Titel des Bildes, Textumgebung und Alt Tag, verstehen bzw. deuten.
Rohdaten aufbereitet: Wie arbeitet der Indexer und wie ist der Index aufgebaut?
Der Indexer hat die Aufgabe, die Rohdaten aus dem Local Store des Crawlers aufzubereiten und einzuteilen, damit diese für die Suche effizient verarbeitet werden können. Aus der Vielzahl an Dokumenten wird dabei ein Index erstellt, der eine Repräsentation darstellt. Bei der Suche wird nicht das Dokument selbst gesucht, sondern die vom Indexer erstellt Repräsentation (Index).
Das System der Syntaxanalyse, auch parsing module genannt, zerlegt alle gefundenen Dokumente in Einheiten, wie Wörter und Wortstämme, markiert und speichert diese ab. Analog zu einem Buchregister, wo Begriffe im Buch mit einer Seitenzahl aufgelistet werden, werden Dokumente nach bestimmten Begriffen im Index gelistet. Hier spricht man von einem invertierten Index – man muss nicht das komplett Buch durchlesen, um zu einem bestimmten Begriff zu kommen, sondern kann direkt zur entsprechenden Stelle blättern. Ähnlich ist auch der Suchmaschinen-Index aufgebaut. Ein invertierter Index und ein Buchregister unterschieden sich aber dahingehend, dass in einem Buchregister nicht immer alle Wörter, die im Buch zu finden sind, vorkommen, sondern nur die für den Textabschnitt sinngemäßen. Bei einer Repräsentation kann bei einer Suchanfrage nach einem bestimmten Begriff nichts gefunden werden, wenn dieser nicht in der Repräsentation zu finden ist. Darin unterscheidet sich ein Invertierter Index von einem Buchregister.
Durch die große Masse an Dokumenten im WWW gibt es, um die Suchergebnisse möglichst schnell für den User bereitzustellen, verteilte Indizes – es gibt nicht einen großen Index, sondern mehrere verteilte Systeme. Dadurch können die Indizes effizient durchsucht und aktuell gehalten werden. Dank des von Google erfundenen MapReduce-Algorithmus ist die Suchmaschine in der Lage, besonders schnell große Datenmengen auf vielen verteilten Rechnern zu crawlen und zu indexieren.
Wie die Suchmaschine Suchanfragen versteht: Der Searcher
Um den Nutzern der Suchmaschine die passenden Ergebnisse präsentieren zu können, braucht es einen Vermittler, den Searcher. Dieser gleicht die Suchanfrage mit dem aufbereiteten Datenbestand der Suchmaschine ab. Die Ergebnisliste wird nach Vorgaben und Rankingfaktoren der Suchmaschine sortiert und abgebildet. Der Searcher hat also die Aufgabe, die Suchanfrage (den Search Intent des Nutzers) zu verstehen und dem Nutzer entsprechende richtige Ergebnisse anzuzeigen.
Um dem User besonders bei komplexen Suchanfragen relevante Ergebnisse ausspielen zu können, behelfen sich Suchmaschinen mit der Anfrageinterpretation. Die Suchanfrage wird dabei mit Kontextinformationen verknüpft, wie der Suchhistorie des Nutzers, seinen Klicks auf bestimmte Ergebnisse, den Pfaden anderer Nutzer mit ähnlichem Suchverlauf und vielem mehr. Durch diese Interpretation, auch query understanding genannt, ist es dem Searcher möglich, relevante Ergebnisse zu komplexen Suchanfragen anzuzeigen.
Zusammenfassung
Auch wenn eine Suchmaschine den Anspruch hat, alle möglichen Dokumente im Netz zu finden und für den User bereitzustellen, ist dies nicht möglich, da zum einen die Masse an Dokumenten extrem groß ist und es zum anderen Seiten gibt, die keine Verlinkungen haben oder Seiten, die eben nicht von klassischen Suchmaschinen gefunden werden wollen und über ein Passwort geschützt sind.
Die Suchmaschinen haben trotzdem für uns User das Internet greifbar gemacht und ermöglichen es, darin nach relevanten Informationen zu suchen. Dieser Artikel hat nur an der Oberfläche gekratzt, in einem der nächsten Blogartikel werde ich näher auf das Thema der Information Retrieval eingehen. Information Retrieval bedeutet gespeicherte, unstrukturierte Informationen aufrufbar und auswertbar zu machen. Dies kann als die Wissenschaft hinter den Suchmaschinen bezeichnet werden.
Quellen:
- https://www.springer.com/de/book/9783662440148
- http://infolab.stanford.edu/~backrub/google.html
- http://www.bui.haw-hamburg.de/fileadmin/user_upload/lewandowski/doc/Web_Information_Retrieval_Buch.pdf
- https://digibib.hs-nb.de/file/dbhsnb_derivate_0000001941/Bachelorarbeit-Schuldt-2015.pdf
- https://www.enzyklopaedie-der-wirtschaftsinformatik.de/wi-enzyklopaedie/lexikon/daten-wissen/Wissensmanagement/Knowledge-Engineering/Suchmaschinen
Update – noch ein schönes Video, wie die Suchmaschine Google funktioniert



