
Wofür benötigt man prinzipiell eine Datenbank?
Bei den meisten Herstellern von Datenbanksystemen handelt es sich um SQL-Datenbanken. SQL steht dabei für Structured Query Language, also eine Abfragesprache für strukturierte Daten. Eine solche Abfrage sieht z.B. so aus:
SELECT * FROM customer WHERE plz=8*
Gar nicht so schwer zu verstehen (erstmal :-)). Damit ist also eine SQL-Datenbank für alles geeignet, was strukturierte Daten (Vorname, Nachname, PLZ etc. oder Artikelname, Artikelnummer, Preis etc.) anbelangt. Die SQL-Datenbank von Microsoft heißt praktischerweise Microsoft SQL Server. Bei anderen Herstellern DB2 (IBM), MySQL (OpenSource), Oracle Database 11g, Informix, etc.
Da Microsoft die Wiederverwendbarkeit von Softwarebausteinen als Ziel hat, gilt auch hier: möglichst immer den Baustein SQL Server verwenden für alles, was Strukturierte Daten hat. Dies sind in der Tat eine Menge weiterer Produkte.
Das zweite Ziel einer SQL Datenbank ist natürlich nicht nur die Daten zu managen, sonder auch Auswertungswerkzeuge, um die Daten zu analysieren – Business Intelligence.
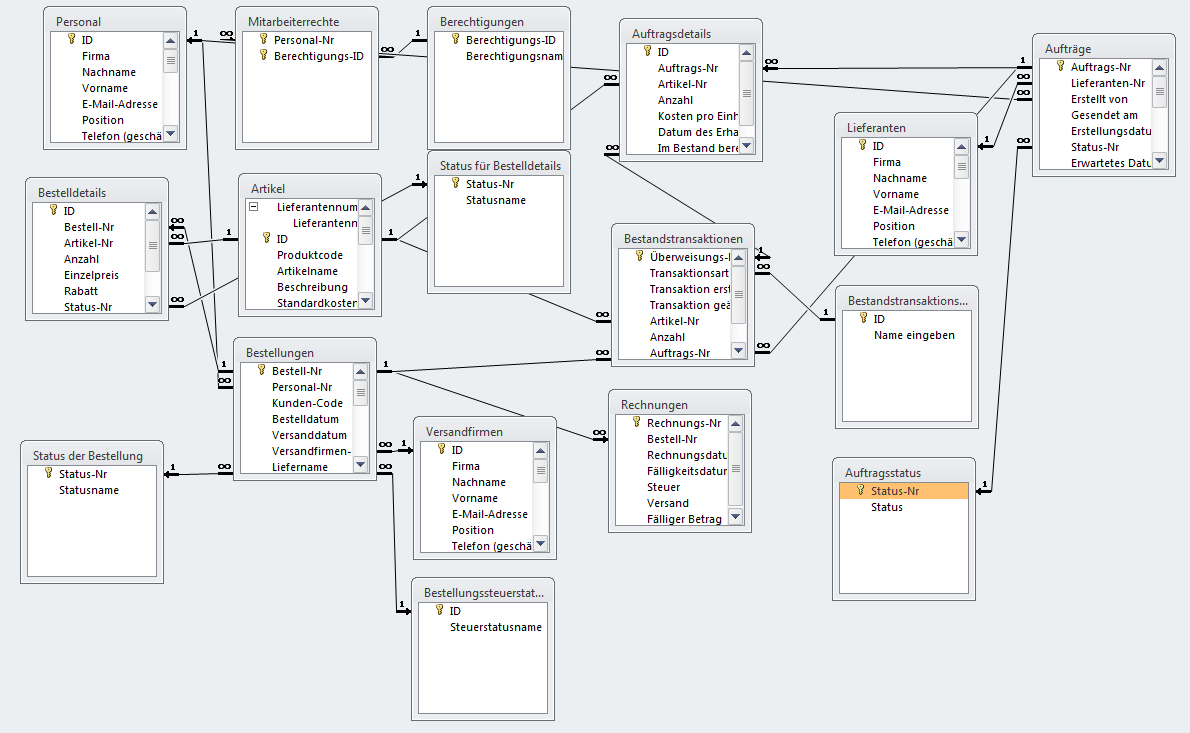
Das Relationale Datenbank Management System RDBMS
Relationales Datenbank Management System RDBMS ist dabei ebenfalls ein gern verwendeter Name für SQL-Datenbanken. Die Idee ist dabei, miteinander verknüpfte Tabellen so herunterzubrechen (normalisieren), dass kein Feld zweimal vorkommt. So muss z.B. der Nachname eines Kunden, egal ob er in 20 Bestellungen oder 13 Rechnungen auftaucht, immer nur an einer einzigen Stelle geändert werden, sollte er sich ändern. Die Beziehungen zwischen den Tabellen (Relationen) müssen dabei ganz sauber definiert sein und das kann dann schon mal so aussehen: (und das ist ein einfaches! Beispiel der beliebten Access-Beispieldatenbank Nordwind.)
SQL Server Instanzen und Datenbanken
Jetzt haben große Unternehmen nicht nur eine Datenbank, sondern viele verschiedene für viele verschiedene Zwecke. Dazu muss nicht jedesmal ein neuer SQL Server installiert werden, sondern mann kann „Instanzen“ des SQL Servers starten. z.B. wie hier in Contoso:

Datawarehouse, Data Mart, OLAP Cubes und ETL
Richtig spannend wird es, wenn dann nicht nur mehrere SQL Server mit mehreren Instanzen sondern auch noch unterschiedliche Datenbanken, die weltweit verteilt sind, eine Rolle spielen. So hat dieses Unternehmen die Fertigungsplanungsdatenbank-Lösung sagen wir in China laufen auf Basis eines Microsoft SQL Servers, das Markting wird von Deutschland aus gemacht mit einer selbstprogrammierten MySQL Datenbank. Das Controlling sitzt in Irland und verwendet SAP wohingegen der Vertrieb auf sagen wir SIEBEL-Datenbanken eingerichtet wurde.
Nun auf die Idee zu kommen, aus all diesem Datenwust genau die Daten herauszufiltern, die dem Unternehmen helfen, fundierte Entscheidungen zu treffen, stellen es technisch zunächst mal vor eine große Herausforderung:
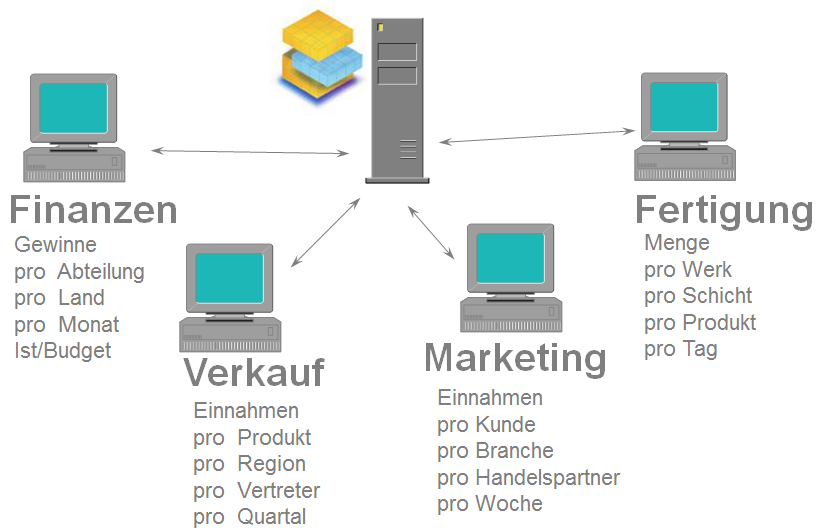
Die verteilten Datenbanken müssen über Schnittstellen verbunden werden, das machen Integrations Dienste. Dann müssen die Daten extrahiert, transformiert und geladen werden (ETL) und in ein einfaches Data Mart überführt werden, darauf wird ein Analyse-Cube aufgebaut, der mit Excel dynamisch abgefragt werden kann, dann werden produktive Berichte erstellt die im Intranet veröffentlicht.
Analysebäume, Auswertungstools, ein OLAP-Cube Server sowie Reporting Dienste runden das Business Intelligence Thema ab.
Der Microsoft SQL Server ist ein RDBMS, das alle diese BI-Werkzeuge enthält. Produktspezifisches findet sich hier: https://www.skilllocation.com/sql-server-2008-r2.html
Inzwischen sind viele Begriffe im Bereich Datenbanken und Business Intelligence dazugekommen. Mancher macht exakte Unterschiede zwischen Begriffe wie Data Analytics, Data Scientist, Big Data, Hadoop, HD Insight etc.
Für Power BI haben wir eine eigene Seite angelegt: https://www.skilllocation.com/power-bi.html
Mir geht es hier vor allem um das Verständnis dafür, wie wichtig diese Themen für Kunden sind, die Informationen aus ihren Daten herausholen wollen, egal wo diese erstmal liegen und in welcher Form sie vorliegen.